Seq2seq 基础知识
In this post we will learn the foundations behind sequence to sequence models and how neural networks can be used to build powerful models capable of analyzing data that varies over time.
[TOC]
Introduction
Seq2seq is a general-purpose encoder-decoder framework that can be used for Machine Translation, Text Summarization, Conversational Modeling, Image Captioning, and more.
Concepts
Encoder
An encoder reads in “source data”, e.g. a sequence of words or an image, and produces a feature representation in continuous space. For example, a Recurrent Neural Network encoder may take as input a sequence of words and produce a fixed-length vector that roughly corresponds to the meaning of the text. An encoder based on a Convolutional Neural Network may take as input an image and generate a new volume that contains higher-level features of the image. The idea is that the representation produced by the encoder can be used by the Decoder to generate new data, e.g. a sentence in another language, or the description of the image. For a list of available encoders, see the Encoder Reference.
Decoder
A decoder is a generative model that is conditioned on the representation created by the encoder. For example, a Recurrent Neural Network decoder may learn generate the translation for an encoded sentence in another language. For a list of available decoder, see the Decoder Reference.
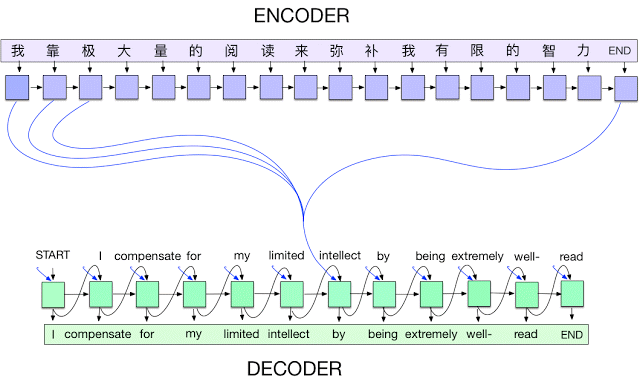
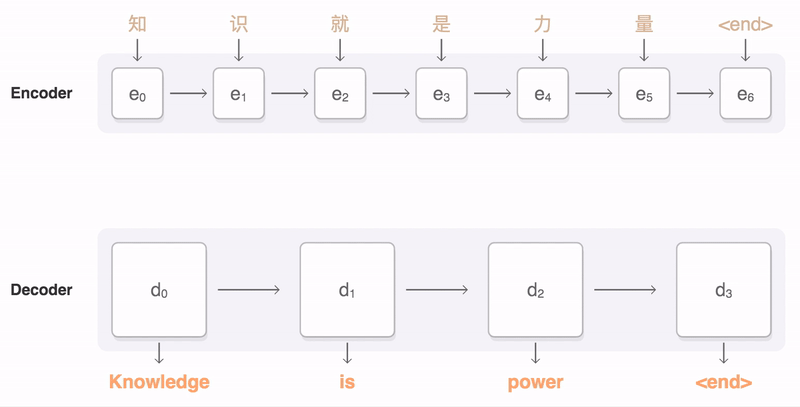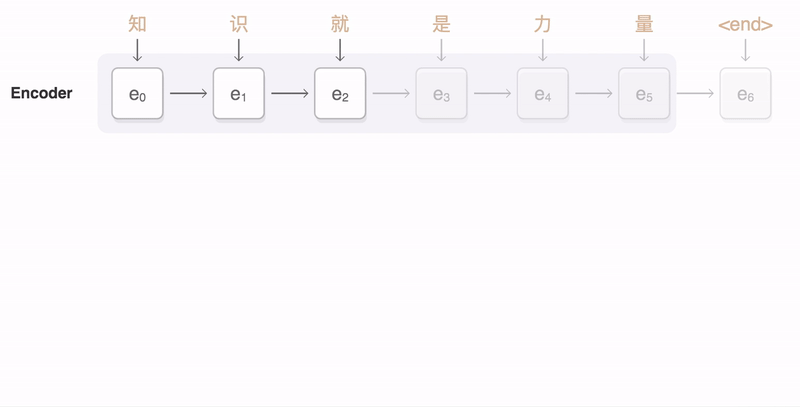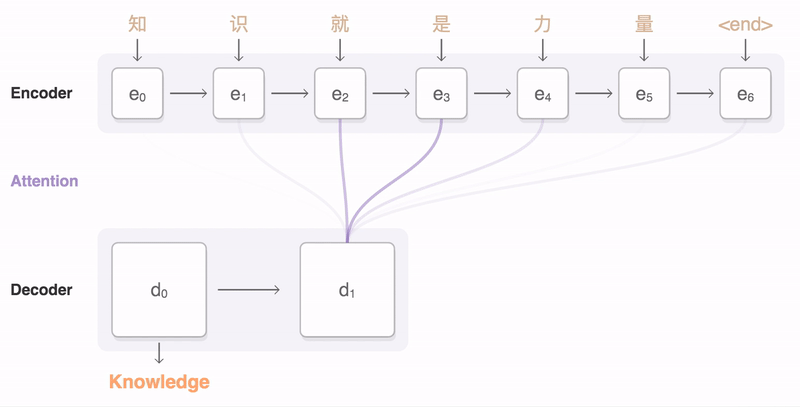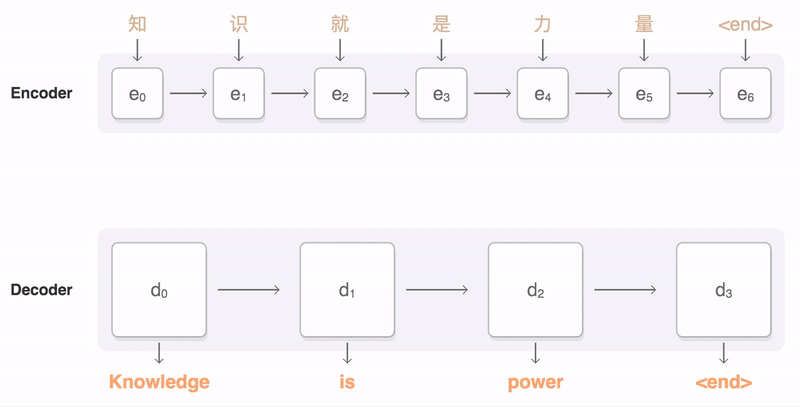
A seq2seq model translating from Mandarin to English. At each time step, the encoder takes in one Chinese character and its own previous state (black arrow), and produces an output vector (blue arrow). The decoder then generates an English translation word-by-word, at each time step taking in the last word, the previous state, and a weighted combination of all the outputs of the encoder (aka attention [3], depicted in blue) and then producing the next English word. Please note that in our implementation we use wordpieces [4] to handle rare words.
Model
Based on this tutorial Unlike simple language models that just try to predict a probability for the next word given the current word, RNN models capture the entire context of the input sequence. Therefore, RNNs predict the probability of generating the next word based on the current word, as well as all previous words.
Sequence to sequence models build on top of language models by adding an encoder step and a decoder step. In the encoder step, a model converts an input sequence (such as an English sentence) into a fixed representation. In the decoder step, a language model is trained on both the output sequence (such as the translated sentence) as well as the fixed representation from the encoder. Since the decoder model sees an encoded representation of the input sequence as well as the translation sequence, it can make more intelligent predictions about future words based on the current word.
Now that we understand the basics of sequence to sequence modeling, we can consider how to build a simple neural translation model. For our encoder, we will use an RNN. The RNN will process the input sequence, then pass its final output to the decoder sequence as a context variable. The decoder will also be an RNN. Its task is to look at the translated input sequence, and then try to predict the next word in the decoder sequence – given the current word in the decoder sequence, as well as the context from the encoder sequence. After training, we can produce translations by encoding the sentence we want to translate and then running the network in generation mode. The sequence to sequence model can be viewed graphically in the diagrams below.
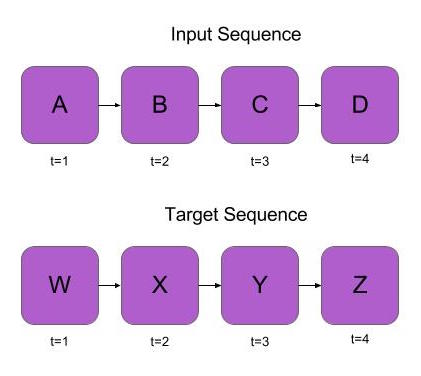
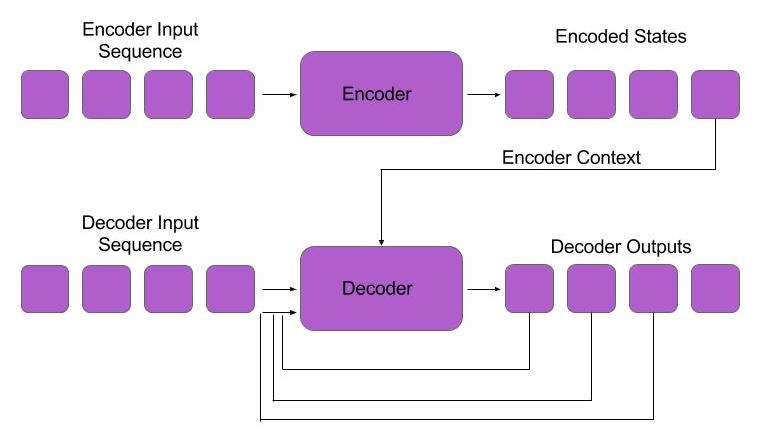
Figure 3: Sequence to Sequence Model – the encoder outputs a sequence of states. The decoder is a language model with an additional parameter for the last state of the encoder.
Attention models
we will see how an attention mechanism can be added to the sequence to sequence model to improve its sequence modeling capacity.
What is Attention?
neural networks that focus on important information while filtering out unnecessary data. Application: language translation
Implementing Attention
The sequence to sequence model gives us the ability to process input and output sequences. Unfortunately, compressing an entire input sequence into a single fixed vector tends to be quite challenging. Moreover, the last state of the encoder contains mostly information from the last element of the encoder sequence. Therefore, the context is biased towards the end of the encoder sequence, and might miss important information at the start of the sequence.
Instead of compressing the entire input sequence into a fixed representation, we can use an attention mechanism. This mechanism will hold onto all states from the encoder and give the decoder a weighted average **of the **encoder states for each element of the decoder sequence. Now, the decoder can take “glimpses” into the encoder sequence to figure out which element it should output next.
Implementing attention is a straightforward modification to our language model. We start by encoding the input sequence with an RNN and hold onto each state it produces. During the decoding phase, we take the state of the decoder network, combine it with the encoder states, and pass this combination to a feedforward network. The feedforward network returns weights for each encoder state. We multiply the encoder inputs by these weights and then compute a weighted average of the encoder states. This resulting context is then passed to the decoder network. Our decoder network can now use different portions of the encoder sequence as context while it’s processing the decoder sequence, instead of using a single fixed representation of the input sequence. This allows the network to focus on the most important parts of the input sequence instead of the whole input sequence, therefore producing smarter predictions for the next word in the decoder sequence. Below is a diagram showing a sequence to sequence model that uses attention during training and generation.
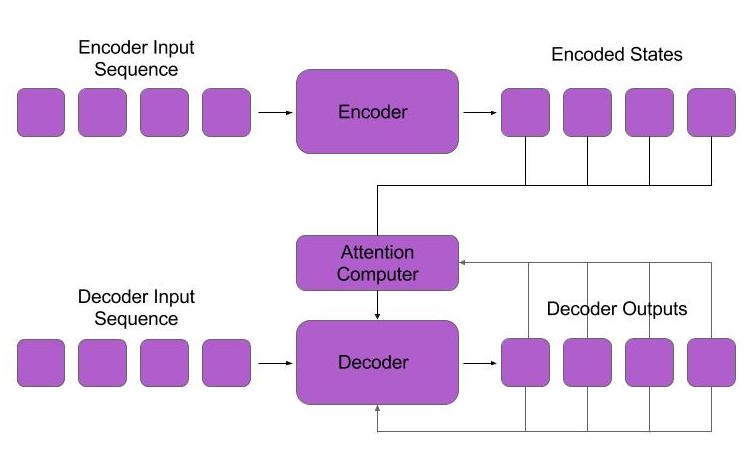
Figure 1. Attention Model: Instead of receiving the last state of the encoder, the attention model uses an attention computer which returns a weighted average of the encoder states.
Example
For this task, we will take in an input sequence of characters and try to translate it into a sequence of characters where each word of the input sequence is reversed. For example, if the input sequence is “the cat sat on the mat”, the sequence to sequence model will try to predict “eht tac tas no eht tam.”
While we could solve this problem with a simple sequence to sequence model, it would be quite challenging to figure out what the reverse of the input sequence is based on a single output from the encoder network. With the attention mechanism, the decoder can focus on the previous character of the input sequence when trying to predict the next element of the output sequence. I have plotted the weighted averages from the attention mechanism to visualize which portion of the input sequence the output decoder is looking at when we make a prediction. We can see that the decoder’s attention is focused on predicting the next element of the output sequence, based on which character came prior to the current character in the input sequence.

Figure 2. Attention Weights: the horizontal axis corresponds to the element of the decoder sequence the decoder is currently operating on. The vertical axis corresponds to the weighted average of the encoder states. Lighter pixels correspond to higher attention at that state from the encoder.
References
[1] Massive Exploration of Neural Machine Translation Architectures, Denny Britz, Anna Goldie, Minh-Thang Luong, Quoc Le [2] Sequence to Sequence Learning with Neural Networks, Ilya Sutskever, Oriol Vinyals, Quoc V. Le. NIPS, 2014 [3] Neural Machine Translation by Jointly Learning to Align and Translate, Dzmitry Bahdanau, Kyunghyun Cho, Yoshua Bengio. ICLR, 2015 [4] Google’s Neural Machine Translation System: Bridging the Gap between Human and Machine Translation, Yonghui Wu, Mike Schuster, Zhifeng Chen, Quoc V. Le, Mohammad Norouzi, Wolfgang Macherey, Maxim Krikun, Yuan Cao, Qin Gao, Klaus Macherey, Jeff Klingner, Apurva Shah, Melvin Johnson, Xiaobing Liu, Łukasz Kaiser, Stephan Gouws, Yoshikiyo Kato, Taku Kudo, Hideto Kazawa, Keith Stevens, George Kurian, Nishant Patil, Wei Wang, Cliff Young, Jason Smith, Jason Riesa, Alex Rudnick, Oriol Vinyals, Greg Corrado, Macduff Hughes, Jeffrey Dean. Technical Report, 2016 [5] Attention and Augmented Recurrent Neural Networks, Chris Olah, Shan Carter. Distill, 2016 [6] Neural Machine Translation and Sequence-to-sequence Models: A Tutorial, Graham Neubig [7] Sequence-to-Sequence Models, TensorFlow.org Share on Google+ Share on Twitter Share on Facebook