Rnn Lstm 基础知识
[TOC]
Introduction
RNN(Recurrent neural Network、循环神经网络)神经网络是一种节点定向连接成环的人工神经网络。这种网络的内部状态可以展示动态时序行为。不同于前馈神经网络的是,RNN可以利用它内部的记忆来处理任意时序的输入序列,这让它可以更容易处理如不分段的语言模型与文本生成(Language Modeling and Generating Text),机器翻译(Machine Translation),语音识别(Speech Recognition),图像描述生成 (Generating Image Descriptions) 等。
RNN-递归神经网络
序列。你可能会问:是什么让递归神经网络如此特殊?Vanilla神经网络(卷积网络也一样)最大的局限之处就是它们API的局限性:它们将固定大小的向量作为输入(比如一张图片),然后输出一个固定大小的向量(比如不同分类的概率)。还不止这些:这些模型按照固定的计算步骤来(比如模型中层的数量)实现这样的输入输出。递归网络更令人兴奋的主要原因是,它允许我们对向量序列进行操作:输入序列、输出序列、或大部分的输入输出序列。通过几个例子可以具体理解这点:
Character-Level Language Models【Source】
We’ll train RNN character-level language models. That is, we’ll give the RNN a huge chunk of text and ask it to model the probability distribution of the next character in the sequence given a sequence of previous characters. This will then allow us to generate new text one character at a time.
As a working example, suppose we only had a vocabulary of four possible letters “helo”, and wanted to train an RNN on the training sequence “hello”. This training sequence is in fact a source of 4 separate training examples: 1. The probability of “e” should be likely given the context of “h”, 2. “l” should be likely in the context of “he”, 3. “l” should also be likely given the context of “hel”, and finally 4. “o” should be likely given the context of “hell”.
Concretely, we will encode each character into a vector using 1-of-k encoding (i.e. all zero except for a single one at the index of the character in the vocabulary), and feed them into the RNN one at a time with the step function. We will then observe a sequence of 4-dimensional output vectors (one dimension per character), which we interpret as the **confidence the RNN **currently assigns to each character coming next in the sequence. Here’s a diagram:
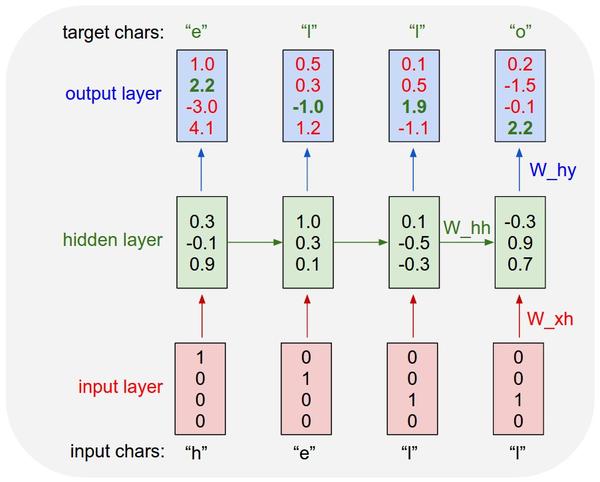
An example RNN with 4-dimensional input and output layers, and a hidden layer of 3 units (neurons). This diagram shows the activations in the forward pass when the RNN is fed the characters “hell” as input. The output layer contains confidences the RNN assigns for the next character (vocabulary is “h,e,l,o”); We want the green numbers to be high and red numbers to be low.
Since the RNN consists entirely of differentiable operations we can run the backpropagation algorithm (this is just a recursive application of the chain rule from calculus) to figure out in what direction we should adjust every one of its weights to increase the scores of the correct targets (green bold numbers). We can then perform a arameter update, which nudges every weight a tiny amount in this gradient direction. If we were to feed the same inputs to the RNN after the parameter update we would find that the scores of the correct characters (e.g. “e” in the first time step) would be slightly higher (e.g. 2.3 instead of 2.2), and the scores of incorrect characters would be slightly lower.
Copy 参数? Copy 了什么?
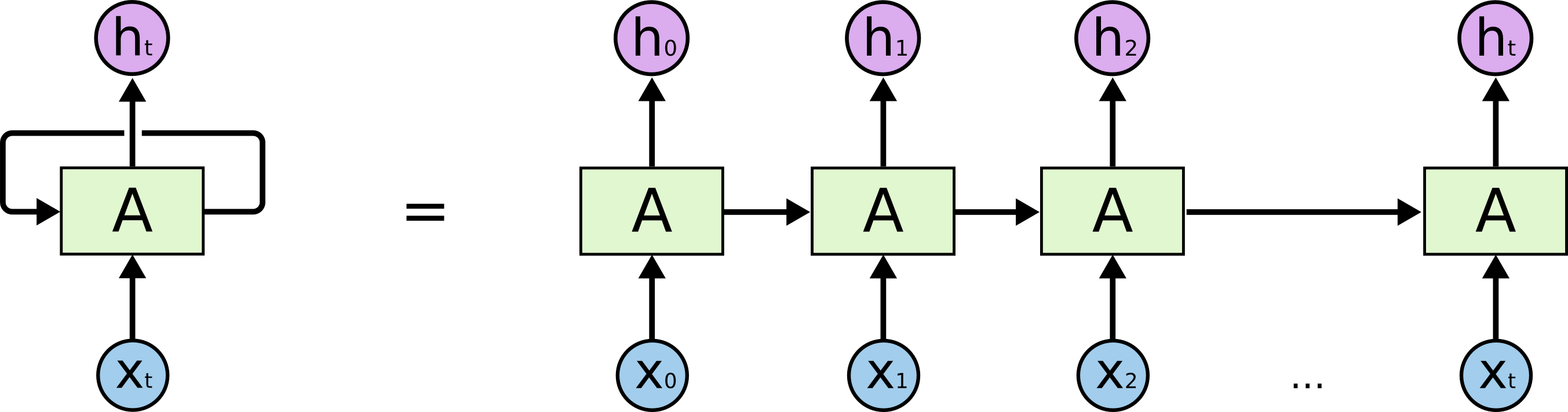
在 t=0 的时候,就是普通的神经网络模型,有3层,两个权重矩阵和 bias,到输出层,预测结果和目标结果计算误差,接着用 BP 去更新 W1 和 W2,但是在 t=1 的时候,就有一个语义层,是从上一个时刻的隐藏层复制过来的,然后和此刻的输入层一起作用到隐藏层,再继续得到结果,再通过 BP 去更新 W1 和 W2。一直这样下去不断地迭代 W1,W2,theta,不断地跑这个时间序列,如果串的长度不到迭代次数,就首尾相连,直到收敛停止迭代。
RNN 基本模型存在某些问题?
It’s entirely possible for the gap between the relevant information and the point where it is needed to become very large.
Unfortunately, as that gap grows, RNNs become unable to learn to connect the information.
- 梯度消失(vanishing gradients)
原因简述:更新模型参数的方法是反向求导,越往前梯度越小。而激活函数是 sigmoid 和 tanh 的时候,这两个函数的导数又是在两端都是无限趋近于0的,会使得之前的梯度也朝向0,最终的结果是到达一定”深度“后,梯度就对模型的更新没有任何贡献。
LSTM
A popular and recommanded tutorial 长短期记忆(LSTM)网络 introduced by Hochreiter & Schmidhuber (1997)。LSTM是一种特殊类型的递归网络,在实践中工作效果更佳,这归功于其强大的更新方程和一些吸引人的动态反向传播功能。
In standard RNNs, this repeating module will have a very simple structure, such as a single tanh layer.
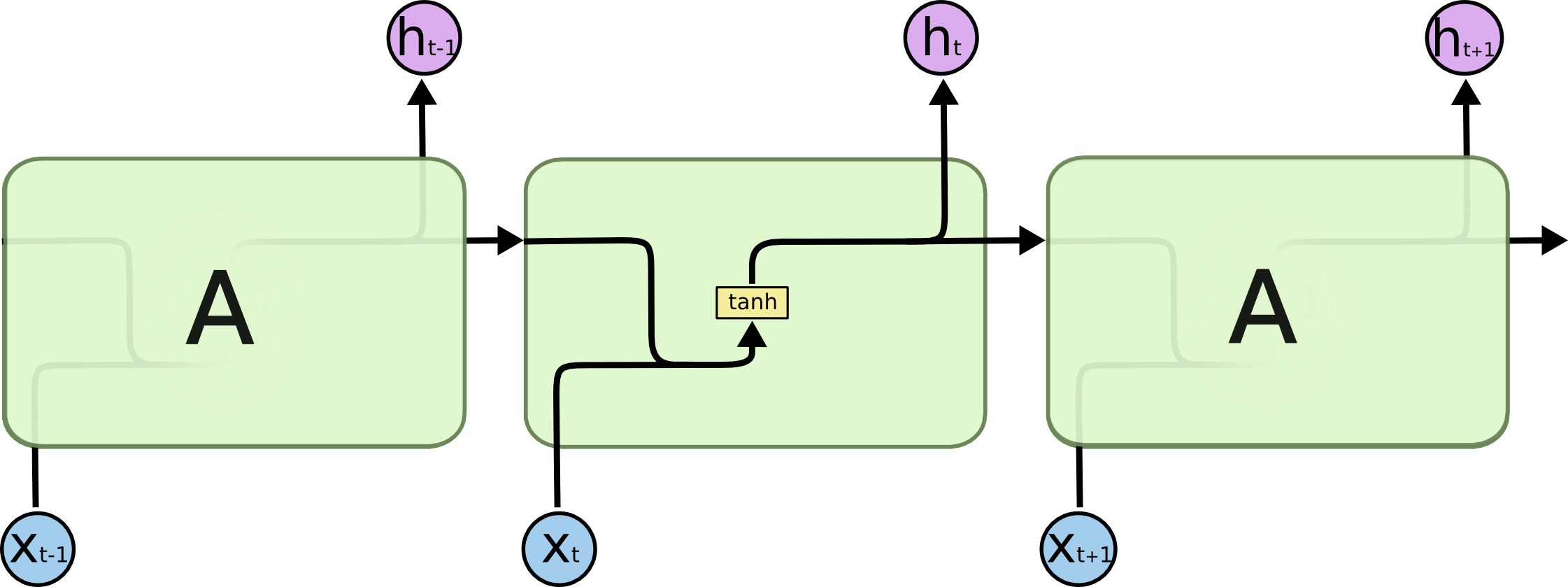
LSTMs also have this chain like structure, but the repeating module has a different structure. Instead of having a single neural network layer, there are four, interacting in a very special way.
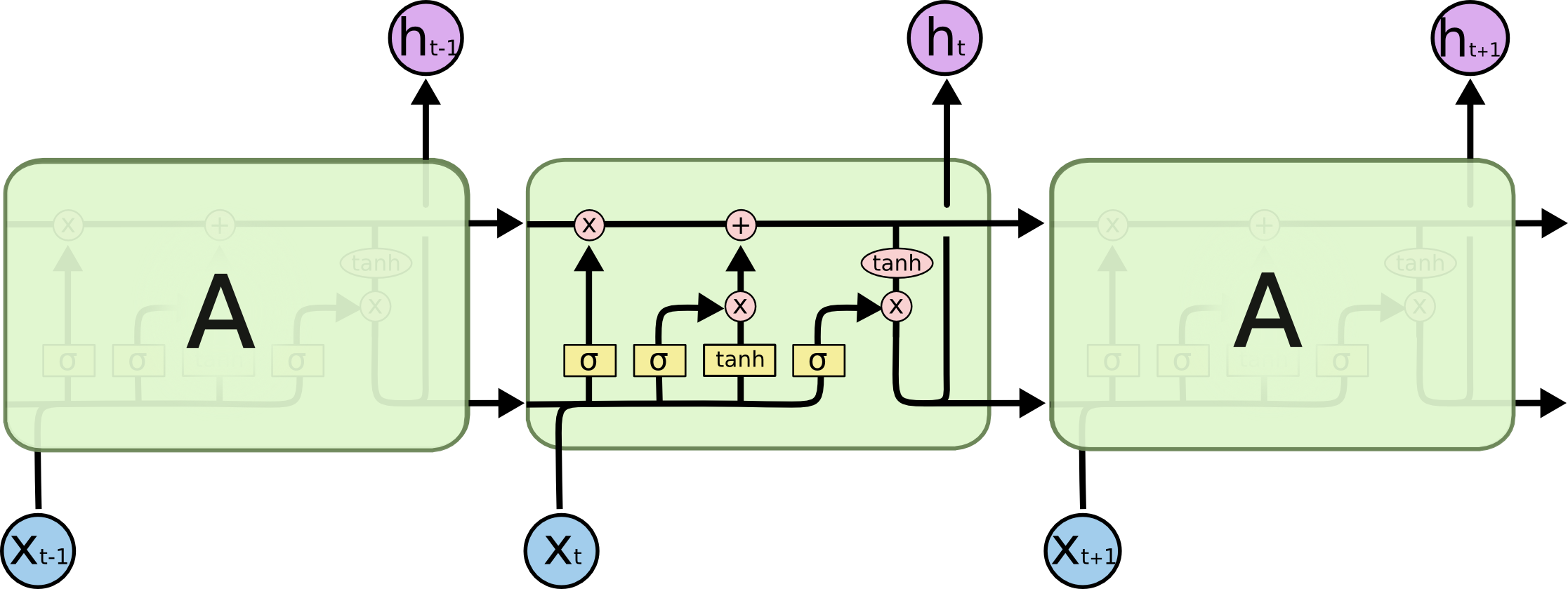
The Core Idea Behind LSTMs
The key to LSTMs is the cell state, the horizontal line running through the top of the diagram.
The cell state is kind of like a conveyor belt. It runs straight down the entire chain, with only some minor linear interactions. It’s very easy for information to just flow along it unchanged.
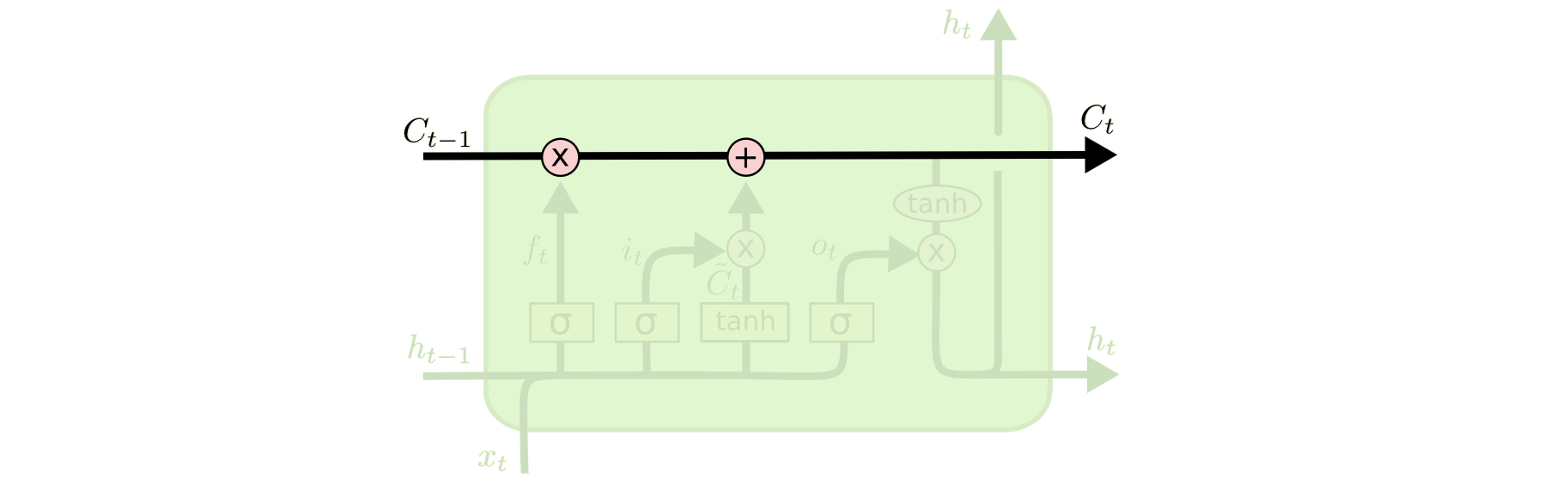
The LSTM does have the ability to remove or add information to the cell state, carefully regulated by structures called gates.
Gates are a way to optionally let information through. They are composed out of a sigmoid neural net layer and a pointwise multiplication operation.
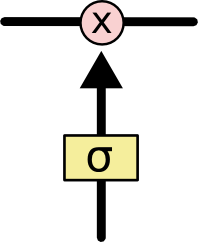 The sigmoid layer outputs numbers
The sigmoid layer outputs numbers between zero and one, describing how much of each component should be let through. A value of zero means “let nothing through,” while a value of one means “let everything through!”
An LSTM has three of these gates, to protect and control the cell state.
Variants on Long Short Term Memory
Attention
总结
神经网络在机器翻译里面比较有名的模型之一就是Encoder–Decoder了,然而在attention机制出来之前,神经网络方法还是没有真正达到传统方法的水平的.
The idea is to let every step of an RNN pick information to look at from some larger collection of information.
For example, if you are using an RNN to create a caption describing an image, it might pick a part of the image to look at for every word it outputs.
原来的Encoder–Decoder
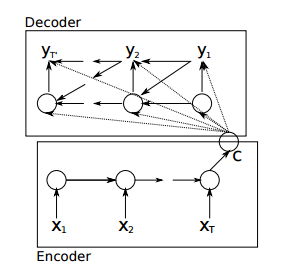
在这个模型中,encoder只将最后一个输出递给了decoder,这样一来,decoder就相当于对输入只知道梗概意思,而无法得到更多输入的细节. 这意味着context越大,最终的state vector会丢失越多的信息。
Attention based model
事实上,因为context在输入时已知,一个模型完全可以在decode的过程中利用context的全部信息,而不仅仅是最后一个state。
Attention based model的核心思想就是如此。如图:
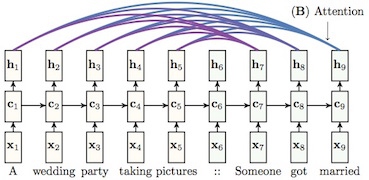
首先,在生成target side的states时 ($h_7, h_8, h_9 $),所有context vectors ($h_1, h_2, h_3…$)都会被当做输入。其次,并不是所有context都对下一个状态的生成产生影响。例如,当翻译英文文章的时候,我们要关注的是“当前翻译的那个部分”,而不是整篇文章。“Attention”的意思就是选择恰当的context并用它生成下一个状态。
如果将生成每个target word前的attention vector拼接起来,可以观察到类似word alignment的有趣矩阵。下图来自paper sentence summarization:
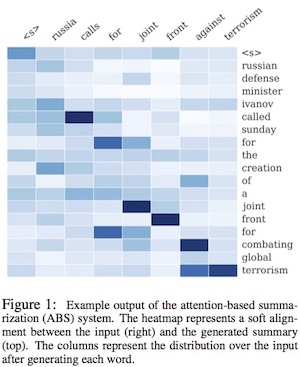
以前我们用网络都是一个卷积模板得到一个特征向量,然后会得到许多个特征向量,每个特征向量通过全连接输入到下一层,每个特征向量的贡献是一样的,但是显然是不合理比如我们做文本翻译的时候,cat and dog,翻译成“猫和狗”,显然cat 对于“猫”的贡献要远超过其他几个单词,所以Attention model 就是来训练这个权重,随着过程的进行,每次特征向量的权重都在变化,比如cat用完了,下一次网络可能就会更加关心and 和 dog这两个单词,所以下一个单词翻译成“和” “狗”的概率会增加,使得最后的结果优于传统的RNN或者CNN网络.[作者:罗浩.ZJU]