Deep Learning 总结
这篇文章的一些截图均来自“一天学会深度学习” – 一个301页的幻灯片,深入浅出的讲解了深度学习的主要内容(我个人非常推荐初学者进行学习)。另外,在知乎,也有非常多的经验分享。
[TOC]
首先,并不是所有的造成“不满意的模型”的原因 都是 overfitting。接下来这些也是可能造成“不满意的模型”的原因。
Loss function
Square Error 和 Cross Entropy 对于不同问题,会造成不同的准确率。选好这个判断标准也是非常重要。
Mini-batch
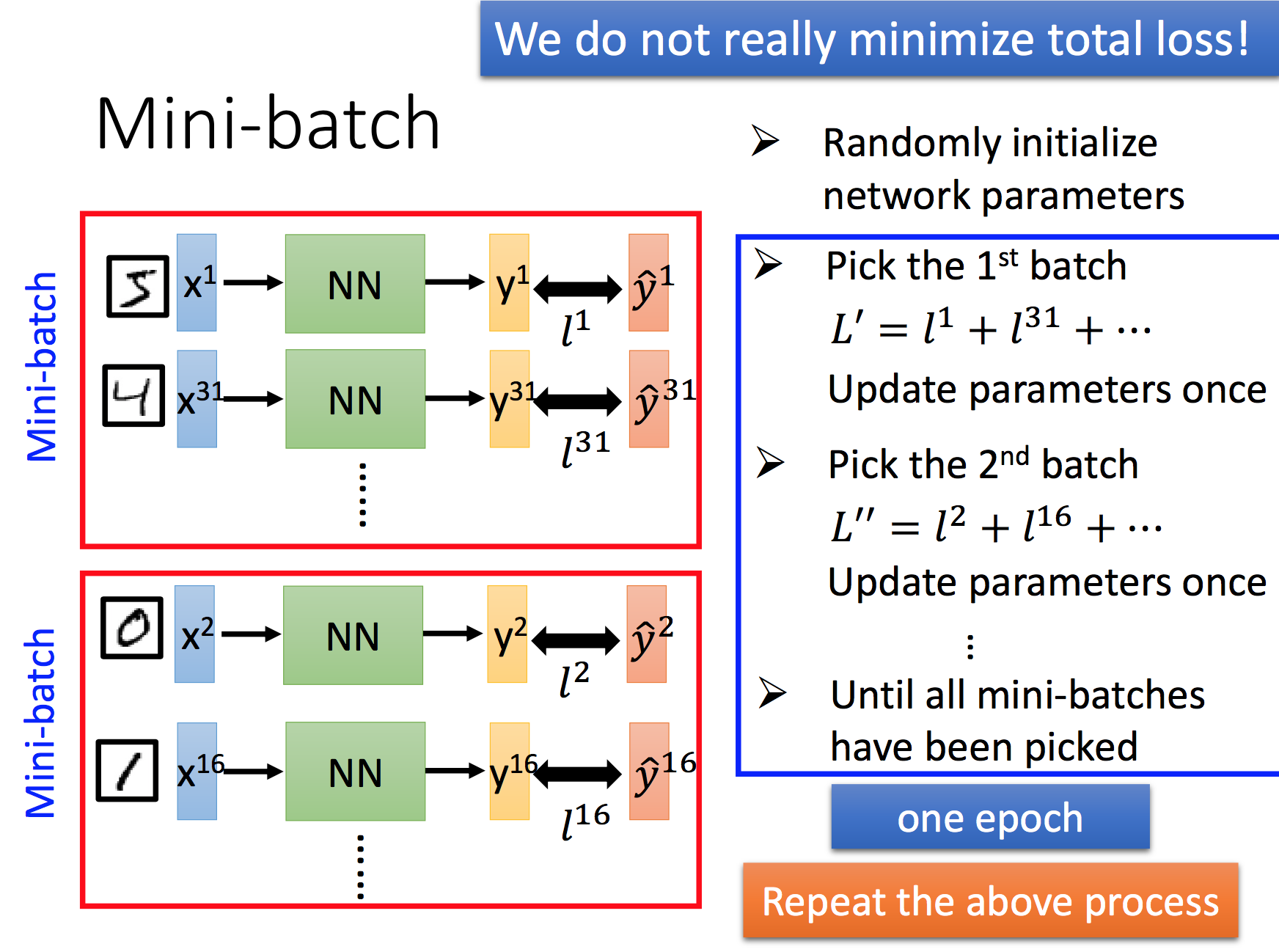
使用Mini-batch的原因是,可以更快的更新参数和训练模型。举个例子,以前是拿到了50000个图片 对于当前模型的 Loss 然后进行 back-propagation,更新参数,现在我们可以在 学习了100个图片后就更新参数,从而更快的收敛函数。背后的原因是,这100个图片所带来的信息量已经足够去更新一次参数,优化一次模型。
另外,需要注意的是Mini-batch可以使Loss function更快的收敛,但并不能帮助我们进一步减小Loss.
Activation function
- Rectified Linear Unit (ReLU)
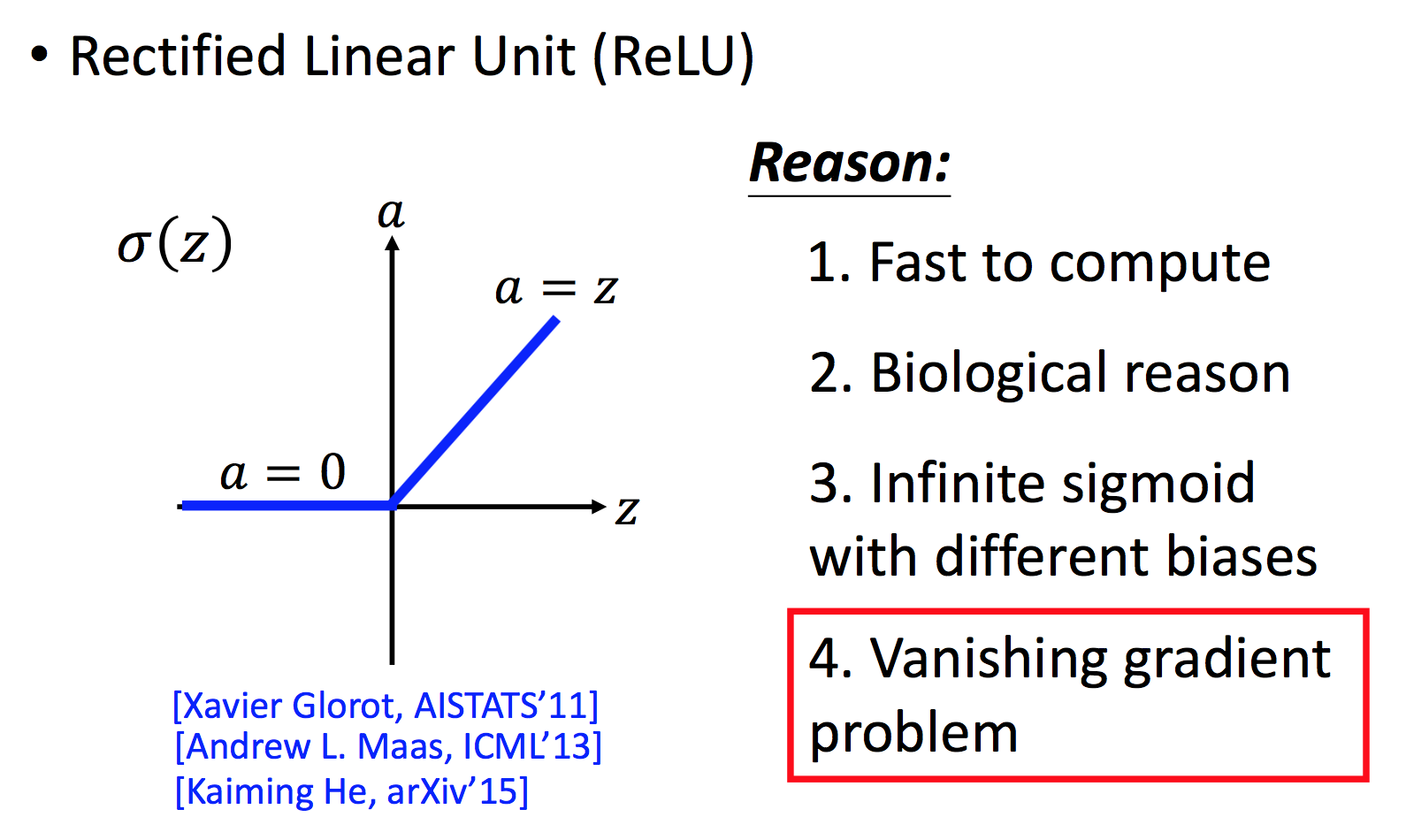
ReLu activation fuction 是当前最火的激活函数,并且逐渐衍生出各式各样的新的激活函数,如,𝐿𝑒𝑎𝑘𝑦 𝑅𝑒𝐿𝑈,𝑃𝑎𝑟𝑎𝑚𝑒𝑡𝑟𝑖𝑐 𝑅𝑒𝐿𝑈。
Adaptive Learning Rate
Learning Rate 过大会造成Loss并没有减小的可能。Learning Rate 过小会造成函数收敛太慢的可能。直觉告诉我们,这个Learning Rate在学习的后期应该逐渐变小,最好呢,有一个自适应的调节。当前已经有很多解决方案,如:Adagrad,Adam.
Momentum
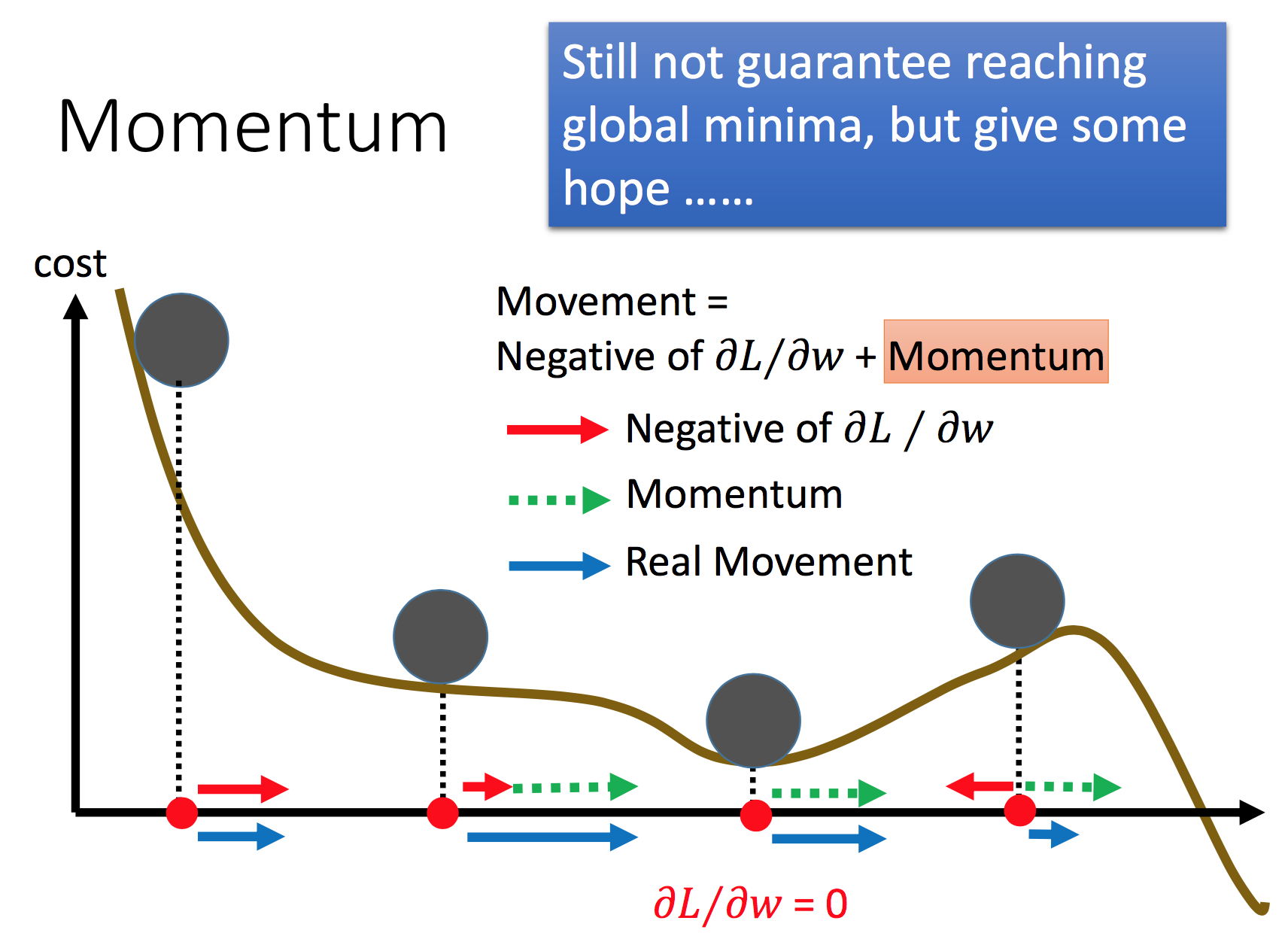
SGD方法的一个缺点是,其更新方向完全依赖于当前的batch,因而其更新十分不稳定。解决这一问题的一个简单的做法便是引入momentum。
momentum即动量,它模拟的是物体运动时的惯性,即更新的时候在一定程度上保留之前更新的方向,同时利用当前batch的梯度微调最终的更新方向(增加了某一方向上的连续性)。这样一来,可以在一定程度上增加稳定性,从而学习地更快,并且还有一定摆脱局部最优的能力.
对于一般的SGD,沿负梯度方向下降。
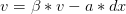
而带momentum项的SGD则写生如下形式:
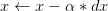
其中 B 即momentum系数,通俗的理解上面式子就是,如果上一次的 momentum(即v) 与这一次的负梯度方向是相同的,那这次下降的幅度就会加大,所以这样做能够达到加速收敛的过程。
Overfitting
Overfitting发生的根本原因是 用 training set 学习来的模型里面的 参数,并不能体现出在 test set 里面的新特性。比如,图像识别里面,数字2的 形状是扭曲的,或者图片背景是新的。有下面几种解决方案:
Early stopping
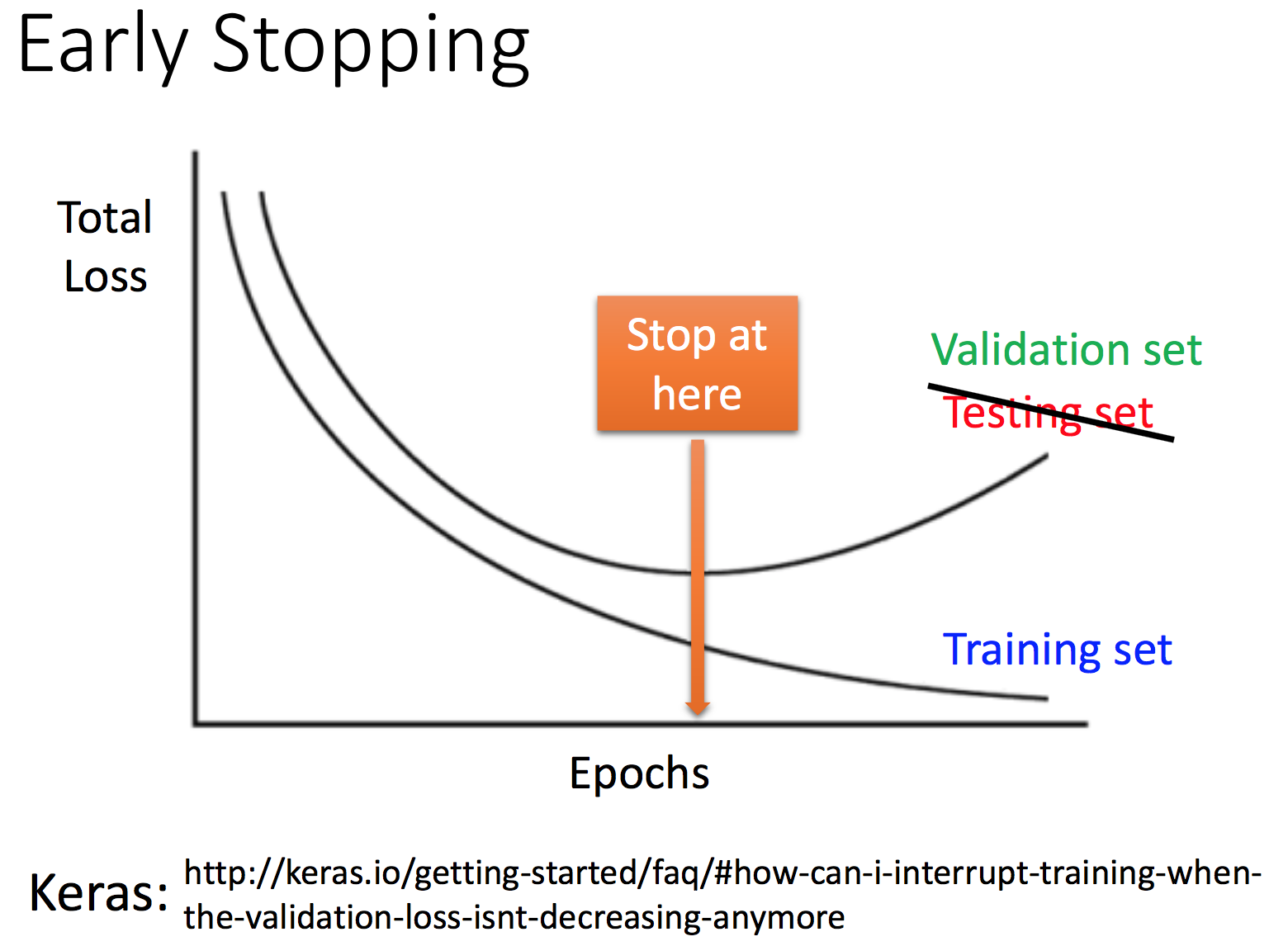
Weight decay

Dropout
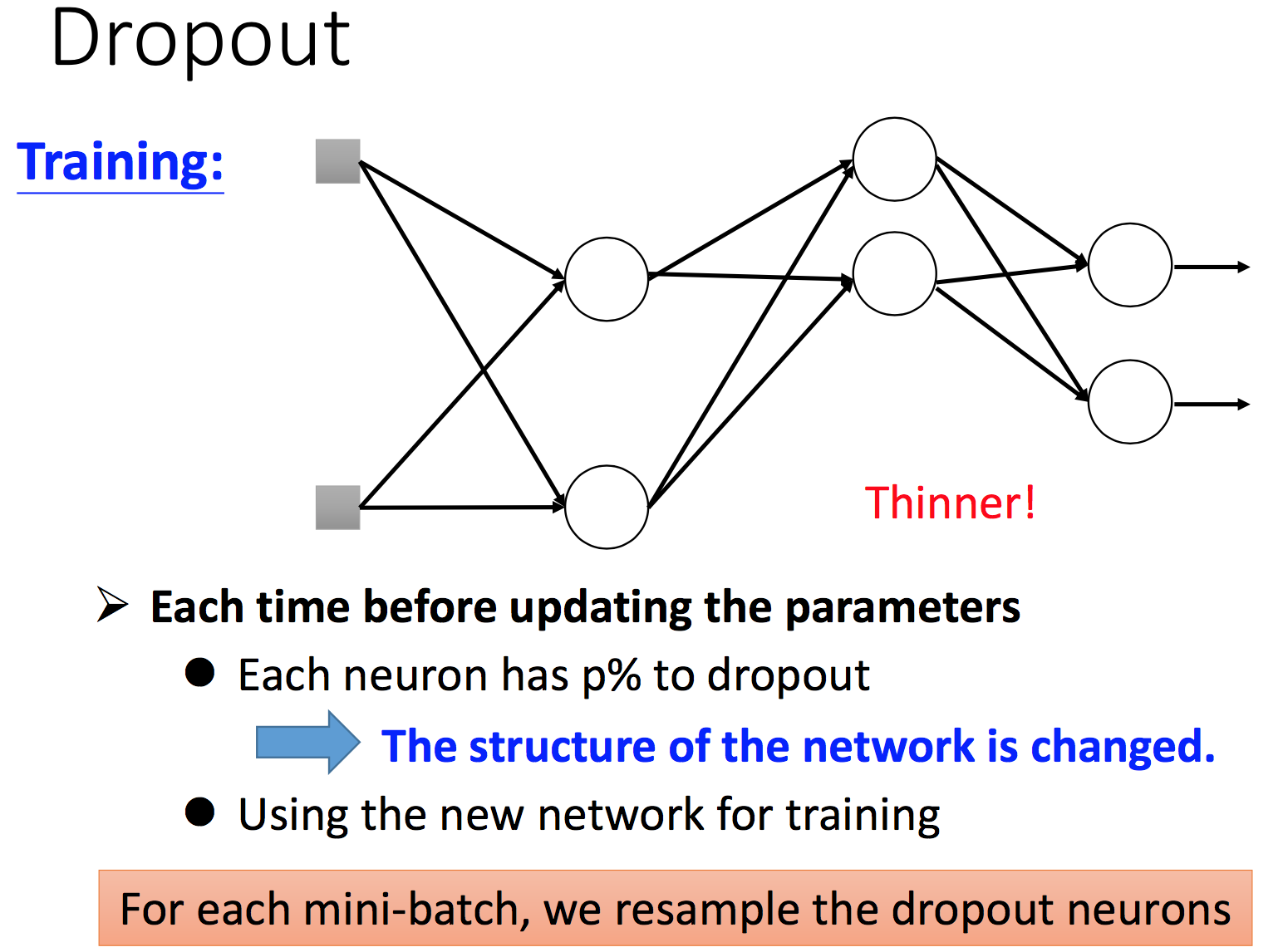
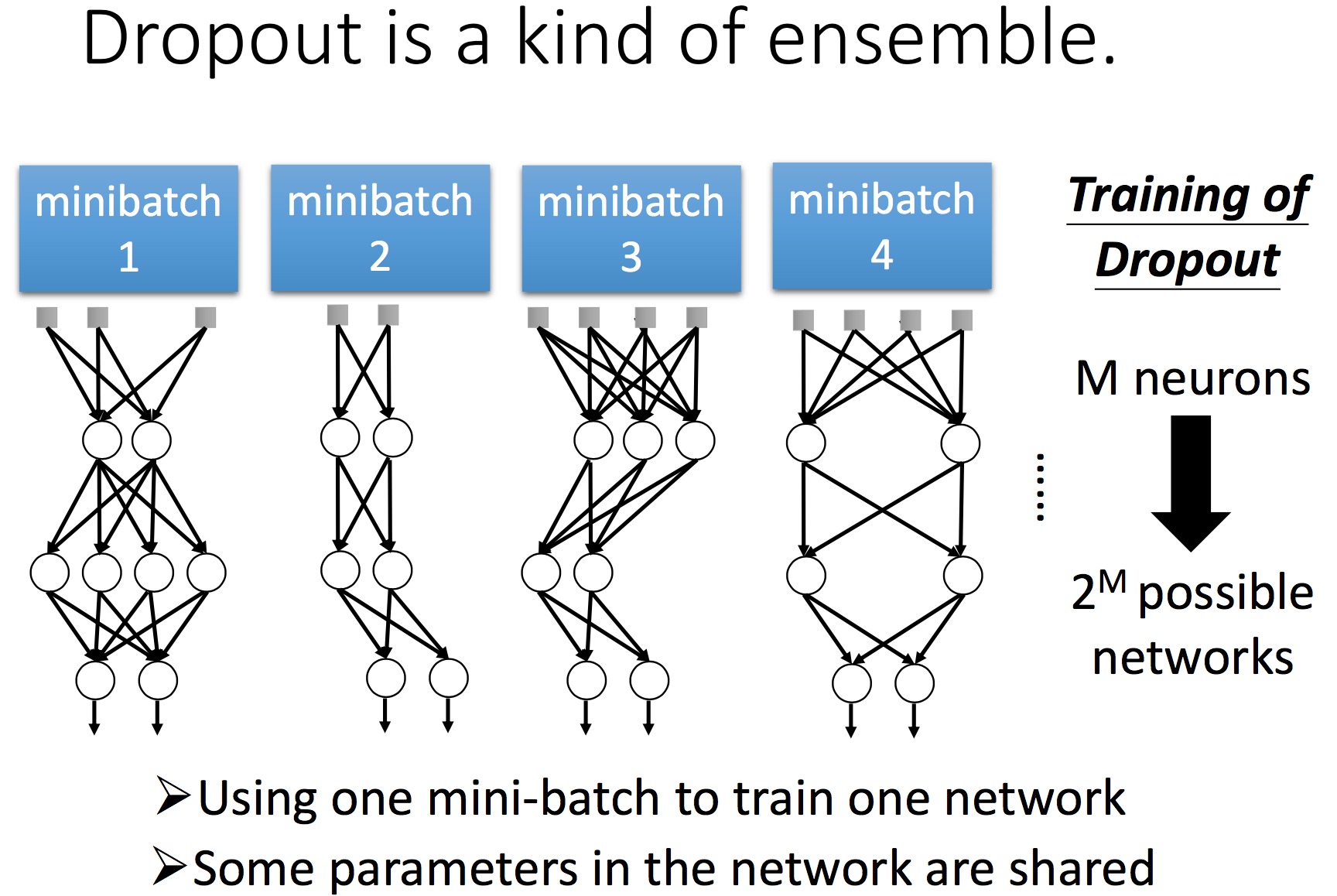
Dropout 去掉了一些参数,使得剩下的参数能够学习足够的信息量。同时,在不同的train set dropout 掉不同的参数,相当于有效训练了多个模型,最后再将多个模型进行整合。
最后,如果依旧overfitting/不理想的结果,那可能就要更换新的模型。
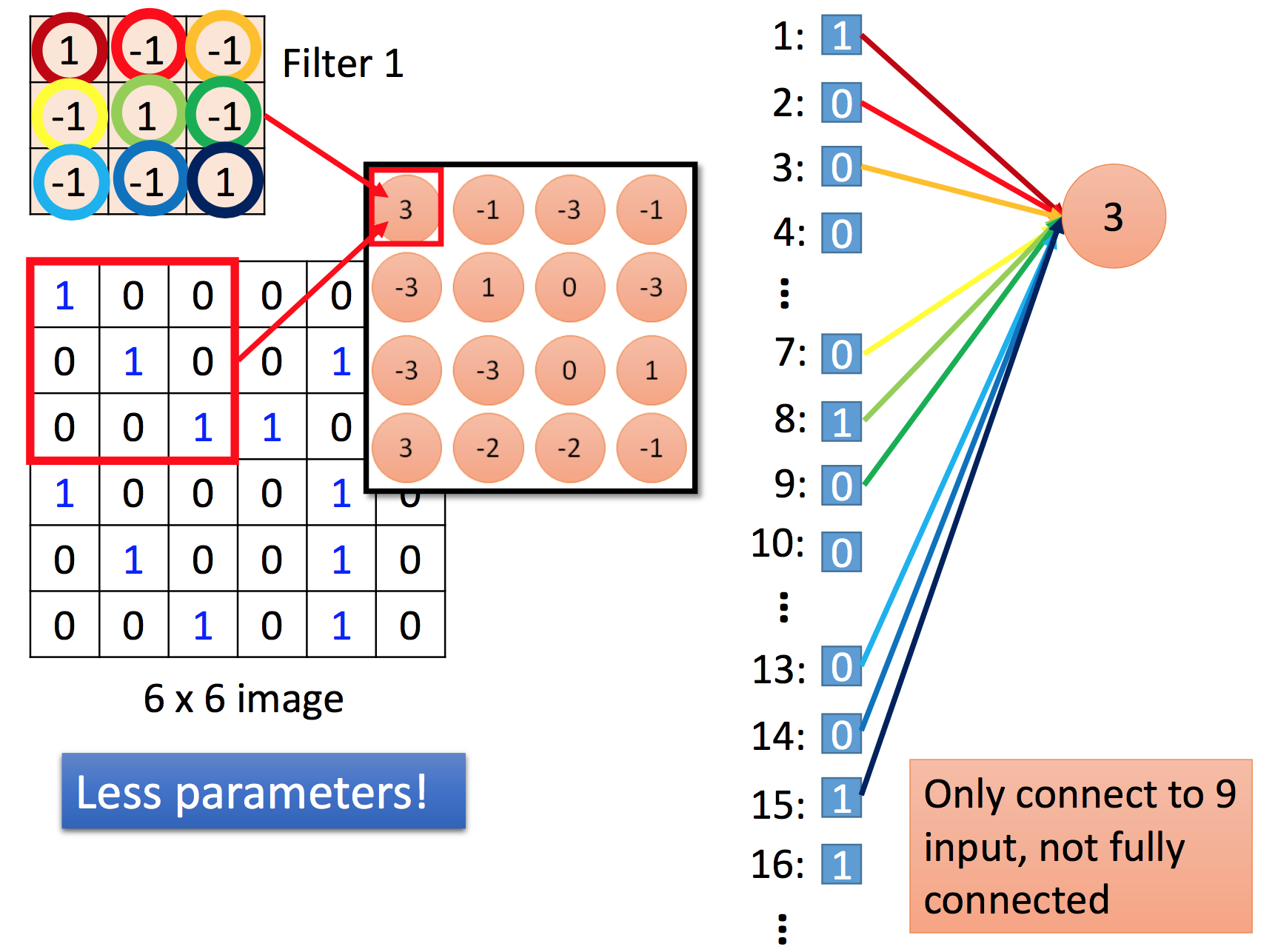
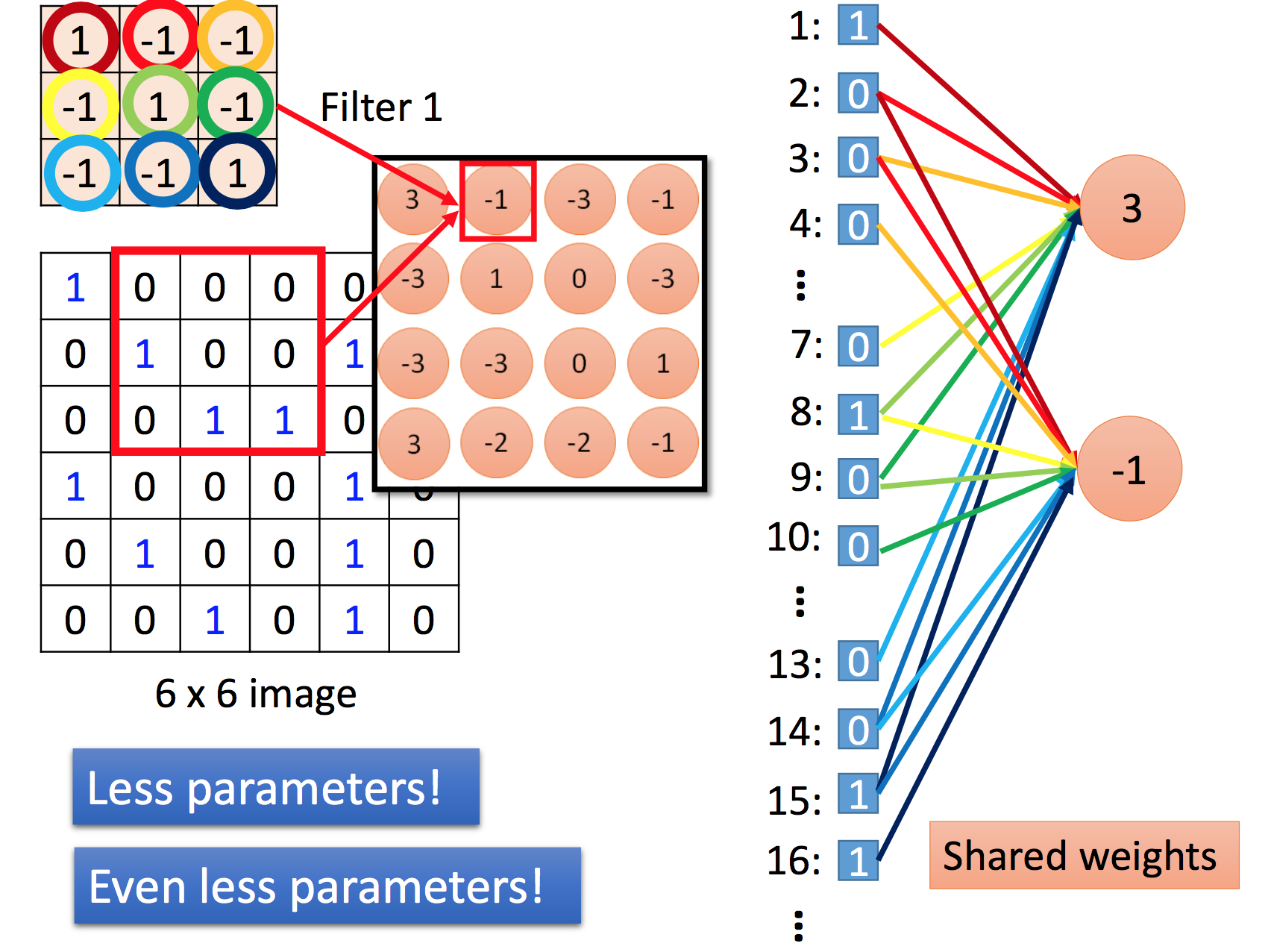
CNN
为什么用CNN

没有必要用 Fully Connected Layer / 1000 个nodes, 图片中细节的 模式 只用一个 3*3 ,或者 5*5大小的维度/filter就可以表现出,比如,人的嘴巴,建筑的棱角。
减少了参数?
Initialization
- uniform
W = np.random.uniform(low=-scale, high=scale, size=shape)
- glorot_uniform
scale = np.sqrt(6. / (shape[0] + shape[1])) np.random.uniform(low=-scale, high=scale, size=shape)
- 高斯初始化:
w = np.random.randn(n) / sqrt(n),n为参数数目
激活函数为relu的话(by Kaiming He),推荐
w = np.random.randn(n) * sqrt(2.0/n)
- svd:
对RNN效果比较好,可以有效提高收敛速度
Xavier initialization
In short, it helps signals reach deep into the network.
If the weights in a network start too small, then the signal shrinks as it passes through each layer until it’s too tiny to be useful. If the weights in a network start too large, then the signal grows as it passes through each layer until it’s too massive to be useful. Xavier initialization makes sure the weights are ‘just right’, keeping the signal in a reasonable range of values through many layers.
One good way is to assign the weights from a Gaussian distribution. Obviously this distribution would have zero mean and some finite variance. Let’s consider a linear neuron:
y = w1x1 + w2x2 + ... + wNxN + b
With each passing layer, we want the variance to remain the same. This helps us keep the signal from exploding to a high value or vanishing to zero. In other words, we need to initialize the weights in such a way that the variance remains the same for x and y. This initialization process is known as Xavier initialization. You can read the original paper here.
Batch_Normalization
Normalization (shifting inputs to zero-mean and unit variance) is often used as a pre-processing step to make the data comparable across features. As the data flows through a deep network, the weights and parameters adjust those values, sometimes making the data too big or too small again - a problem the authors refer to as “internal covariate shift”. By normalizing the data in each mini-batch, this problem is largely avoided.”
归一化后有什么好处呢?
原因在于神经网络学习过程本质就是为了学习数据分布,一旦训练数据与测试数据的分布不同,那么网络的泛化能力也大大降低;另外一方面,一旦每批训练数据的分布各不相同(batch 梯度下降),那么网络就要在每次迭代都去学习适应不同的分布,这样将会大大降低网络的训练速度,这也正是为什么我们需要对数据都要做一个归一化预处理的原因。
作者在文章中强调在训练过程中网络每层输入的分布一直在改变(internal covariate), 会使训练过程难度加大,但可以通过normalize每层的输入解决这个问题。
大家都知道在统计机器学习中的一个经典假设是“源空间(source domain)和目标空间(target domain)的数据分布(distribution)是一致的” ??!!
其他
- 尽量对数据做shuffle!!
- 预处理: -mean/std zero-center
- sgd + momentum(动量).
既然有了深度学习,那是不是以后很多类别的工作都会被取代?
会的,但是...
深度学习工程师的职位不会,因为为某一特定问题,”训练“特定的模型需要十分专业的知识,和长久的经验积累。